
Chris Alexander
24th October, 2016
While I was at DDD North I listened to a very interesting presentation by someone whose main product was an API. Clearly one of their key goals when releasing new features was to ensure that they were backwards compatible – they raised a very good point that most users, once they have set up an API integration, will not change it. And if they do change it – that is a chance for them to move to a competitor.
One of the issues they described was how they had achieved this; if you wanted newer, breaking-change features (e.g. a timestamp moves from UTC to include timezone information) you have to explicitly opt-in; this means that when you start working with the API, you need to decide what features to turn on.
I was thinking about this in the car on the way back down the M1 from Leeds, and will now propose a new method of versioning public APIs that keeps everyone up-to-date who wants to be.
The core to the concept is a date/time stamp or some kind of version identifier. When a developer first integrates with an API, they use in their requests (or is set for them in the client library) a date or other identifier that captures the state of the API at that specific point in time. If you only ever deploy at midnight and once a day, it could be the date stamp (e.g. 2016-10-05). Alternatively, it could be a build number (e.g. 1423, which could increment every time you do a release).
But the key part is that the user sends this identifier every single time they make a request.
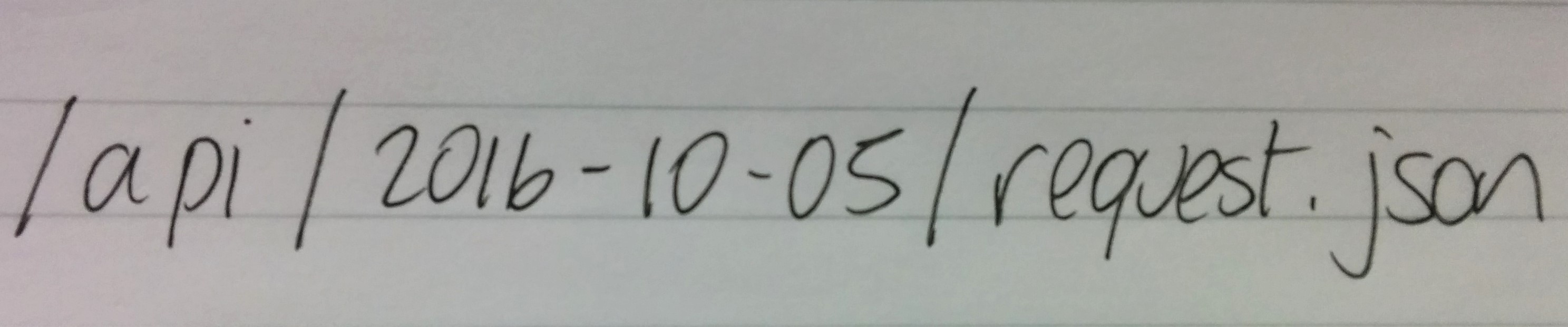
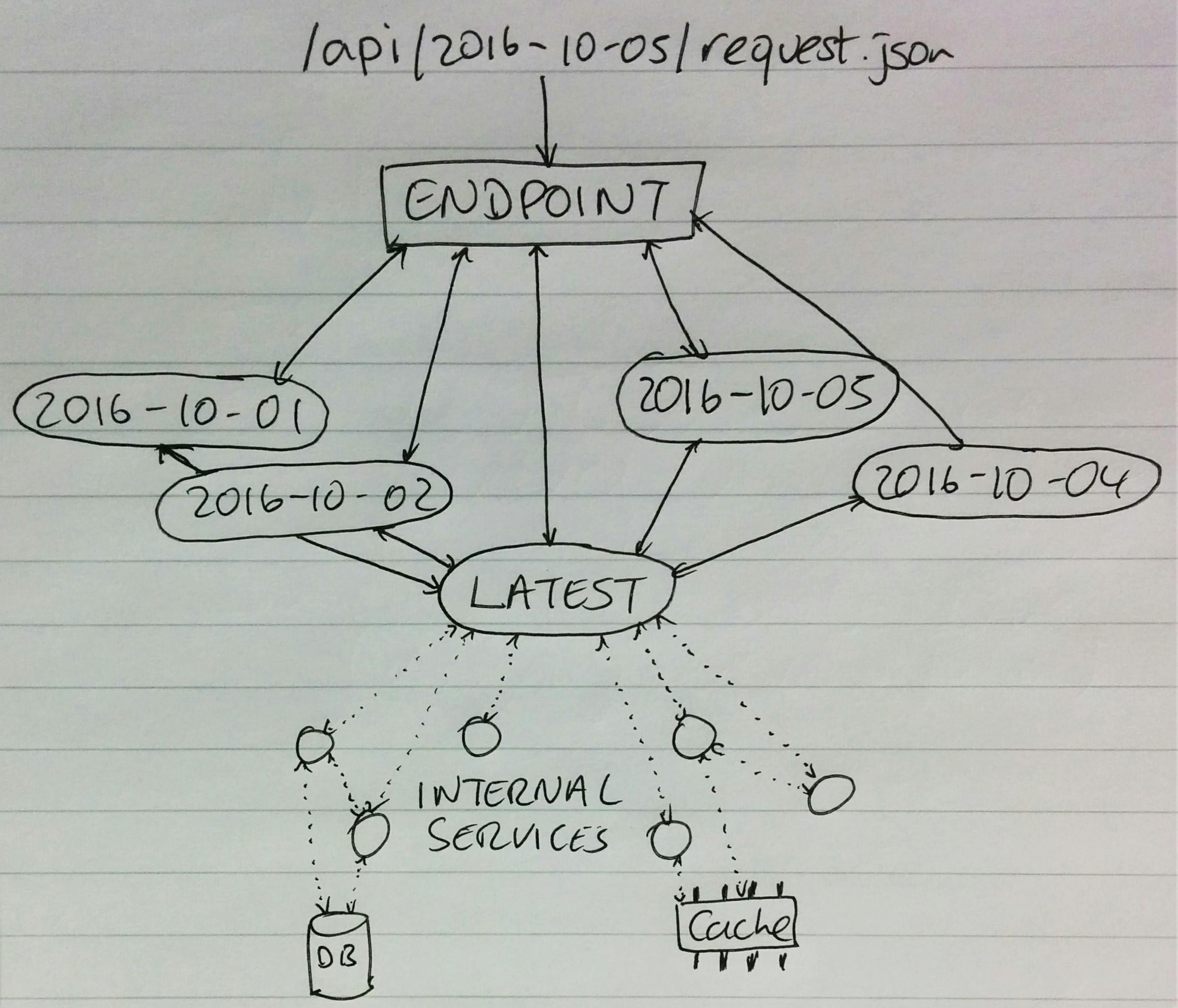
By using this identifier, your API layer can know immediately in what configuration the API was at that time – what features were available or not, what format dates were in, various ID specifications – all the components that make up your API. When the user makes subsequent requests, you can then always serve data to them using the format that they understand.
The beauty of this is that you can support, for some scenarios, almost infinite backwards compatibility. Say you had some kind of microservice model – you could have one service per API version, and they handle the translation to your internal system and always present the data in the same way. This is also super easy to test for backwards compatibility!
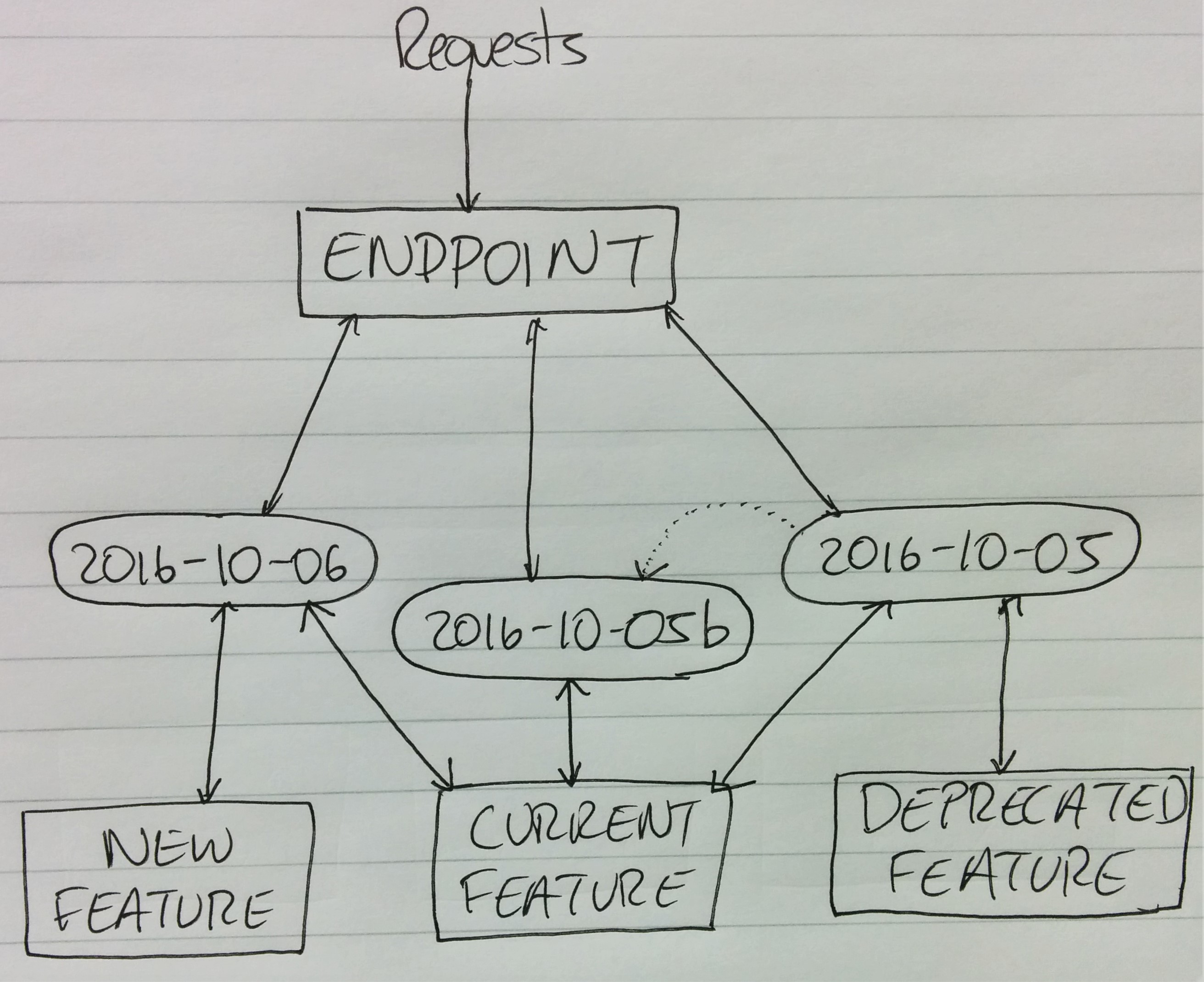
There are a few other advantages as well. If you wish to deprecate an API, simply publishing a new version without it means new users will not ever have access to that API – you could also record the minimum API version for a specific user account, so as to prevent them “going back in time” to something you are trying to roll back.
Additionally, if you introduce new features that users may want, you can put them in new versions only thus ensuring that users who want that feature can get it, in exchange for upgrading to the latest API version and removing them from the pool of users with access to a call you are trying to deprecate. Once you have only a few left, you know which users are still making those requests, and you can contact them separately to ask them to upgrade. You could even create a fork of your old API without the deprecated call in it, allowing them to make one version change without breaking their other APIs.
The ideas of API versioning and backwards compatibility are not new, we are all used to /v1/ and /v2/. However we now have the technology and capability to provide micro-versions in APIs to ensure compatibility for all while keeping people as up-to-date as possible.